
Write Cleaner, More Maintainable Rust Code with PhantomData
Solving the Redundancy Problem: How PhantomData Saves the Day in Rust

I recently encountered a problem while working on an invoice generation project. I found myself dealing with duplicated code when modeling invoice lines with two types of quantities: billed quantity and free quantity. In this blog post, I'll share my experience of using PhantomData to reduce code duplication and improve the overall structure of my code.
The Problem
In my invoice line struct, I wanted to have two separate types for quantities: BilledLineQuantity for billed quantities and FreeLineQuantity for free quantities. The reason for this was to enforce specific validations and ensure that the quantities were always valid. However, this led to a significant amount of duplicated code between the two types.
Initial Approach
I started by defining the BilledLineQuantity and FreeLineQuantity structs separately, each with their own implementations:
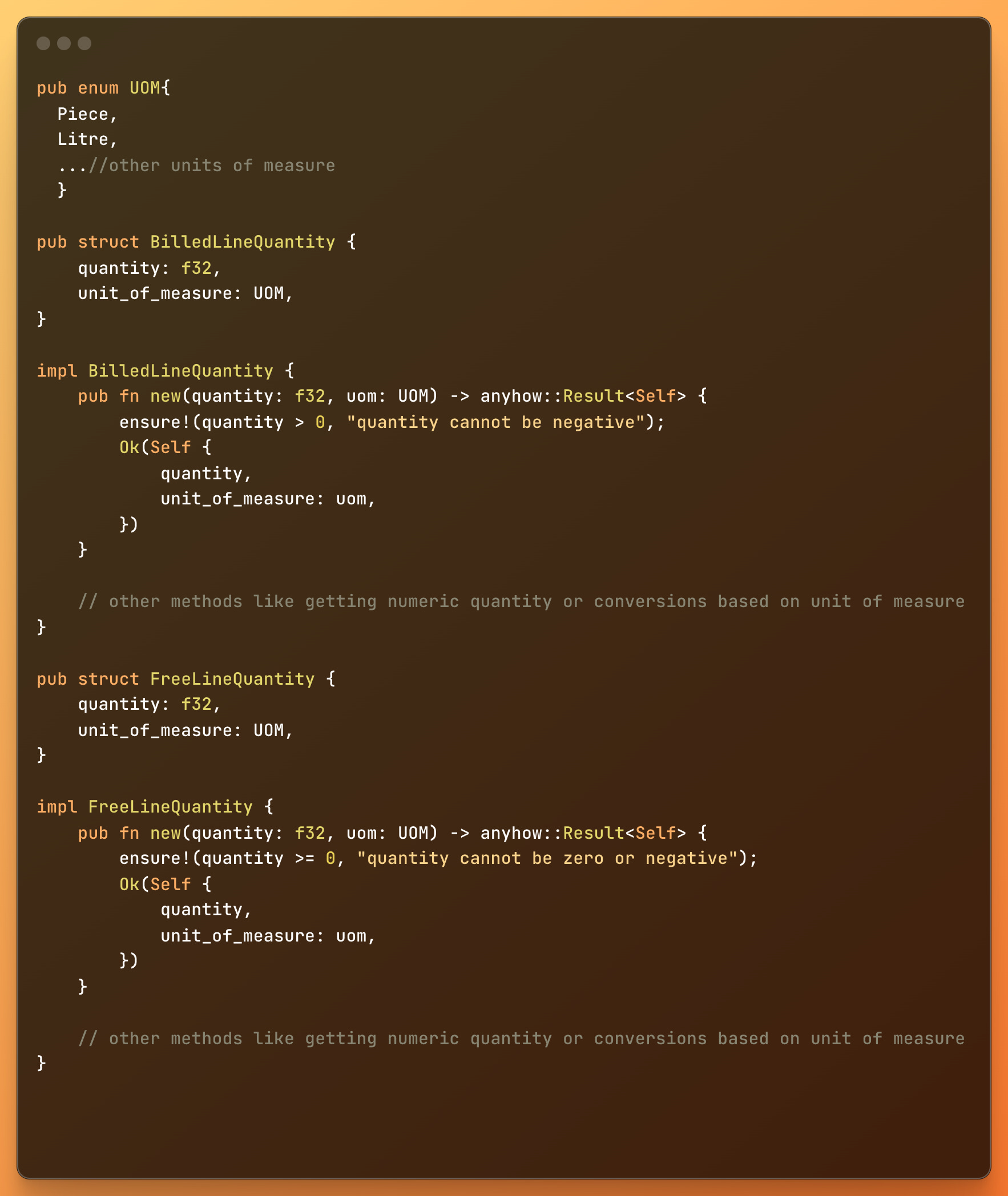
The problem with this approach was that most of the methods for handling quantities, such as getting the numeric value or performing unit of measure conversions, were the same for both types. This resulted in a lot of duplicated code.
Introducing PhantomData
To reduce code duplication, I decided to use PhantomData. PhantomData is a zero-sized type that can be used to mark generic type parameters and provide type-level information without affecting the runtime behaviour.
I created a BaseLineQuantity<T> struct that contained the common fields and methods for both BilledLineQuantity and FreeLineQuantity:

The phantom field of type PhantomData<T> is used to differentiate between the two types.
Refactoring with PhantomData
With the BaseLineQuantity<T> struct in place, I defined two marker types: FreeLineQuantityTag and BilledLineQuantityTag. These types serve as tags to distinguish between the two quantities:
pub struct FreeLineQuantityTag;
pub struct BilledLineQuantityTag;Next, I defined FreeLineQuantity and BilledLineQuantity as type aliases of BaseLineQuantity<T> with their respective tags:
pub type FreeLineQuantity = BaseLineQuantity<FreeLineQuantityTag>;
pub type BilledLineQuantity = BaseLineQuantity<BilledLineQuantityTag>;Finally, I implemented the new method for each type, enforcing the specific validations:

struct InvoiceLine {
billed_quantity: BilledLineQuantity,
free_quantity: FreeLineQuantity,
// other fields
}By leveraging PhantomData, I was able to reduce code duplication and improve the overall structure of my invoice line implementation. PhantomData allowed me to create a generic BaseLineQuantity<T> struct that encapsulated the common fields and methods, while still maintaining type-specific validations through the use of marker types.
This experience taught me the value of using advanced Rust features like PhantomData to solve real-world problems. It's a powerful tool that can help in creating more maintainable and expressive code.
I hope this blog post has provided you with insights into how PhantomData can be used to reduce code duplication in Rust